
Evolving Architecture: Adding value with each change
Not just change for changes sake
The ultimate goal in moving my web-site to AWS is to make it possible to publish articles via a web interface. To build everything necessary to make this possible will take time, so I want to make reasonably small changes that will add value. The first set of changes I made (detailed in Evolving Architecture: Publishing a Jekyll site to AWS using GitHub Actions and AWS CDK) provided a route to getting content on to the internet. But how to actually generate that content? This post provide a high level overview of my next steps.
The current architecture looks like this:
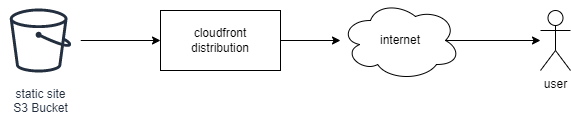
The content is held in the S3 Bucket, and the Cloudfront Distribution mediates access to the bucket from the internet. Simple and straight forward, but right now the site is actually built in a build step and then copied to the bucket. To move away from this is going to require more infrastrucure:
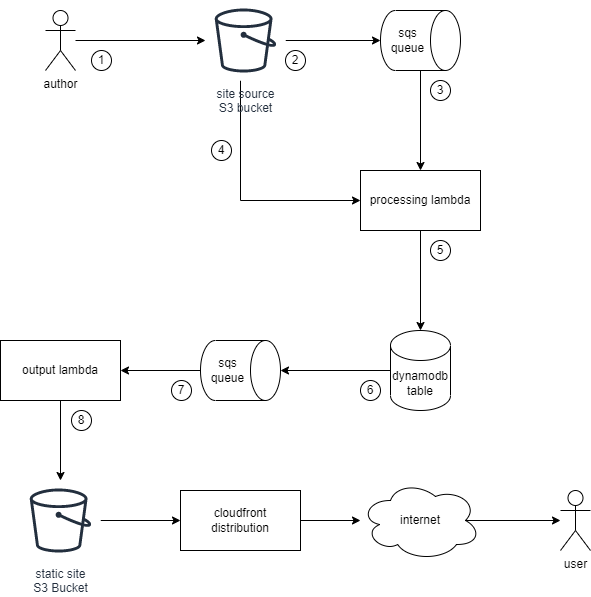
The plan is that with the next set of changes the author (me 😀, also number 1) writes new content to the site source S3 bucket. This causes an event to be written to an sqs queue (number 2), which is then delivered to a lambda to be initially processed (number 3). The lambda will retrieve the file (number 4), and if it is text content write various records to a dynamo db table (number 5). Dynamo db streams processing will then place events in another sqs queue (number 6) which are delivered to an output lambda (number 7) that writes new content to the static site S3 bucket (number 8).
Choices
A number of choice are being made here and it’s valid to question why these choices, and not others?
Why use multiple S3 buckets? Why not use the same bucket for the site source and the formatted output?
This is perhaps the easiest question to deal with, so I’ll answer it first. AWS doesn’t make a charge for the number of buckets you have setup, they only charge for the data you store. Additionally the following warning is published on the first page of the how-to:
If your notification writes to the same bucket that triggers the notification, it could cause an execution loop. For example, if the bucket triggers a Lambda function each time an object is uploaded, and the function uploads an object to the bucket, then the function indirectly triggers itself. To avoid this, use two buckets, or configure the trigger to only apply to a prefix used for incoming objects.
Why are you not sending your events directly to a Lambda?
This is a little tougher, because I probably could get away with slinging the events from the source bucket directly at a Lambda. However I would like flexibility in my design, and may want to use a different lambda to deal with site assets (as an example). By going via an SQS Queue I give myself room to change the receipient further down the line in a more transparent manner.
Why not just trigger the output lambda directly from the processing lambda?
Again it comes back to flexibility. I can trigger the output lambda directly from the processing lambda, I could even create a step function and have each file traverse through a closely coupled pipeline. However at this point I want my components to remain loosely coupled so that I can easily reshape and augment my publishing process.
Database design
So what precisely will be going into the dynamodb table? DynamoDb expects to store data in partitions, you can have as few, or as many as you need, but you need to specify the partition key upfront. This is a little different to other NoSQL databases (e.g. MongoDB) where if you don’t specify a partition or shard key everything gets put in the default. It’s important that the partition key will be well distributed. However DynamoDb also allows us to specify a sort key, which means we can start doing interesting things with the records that we’re storing.
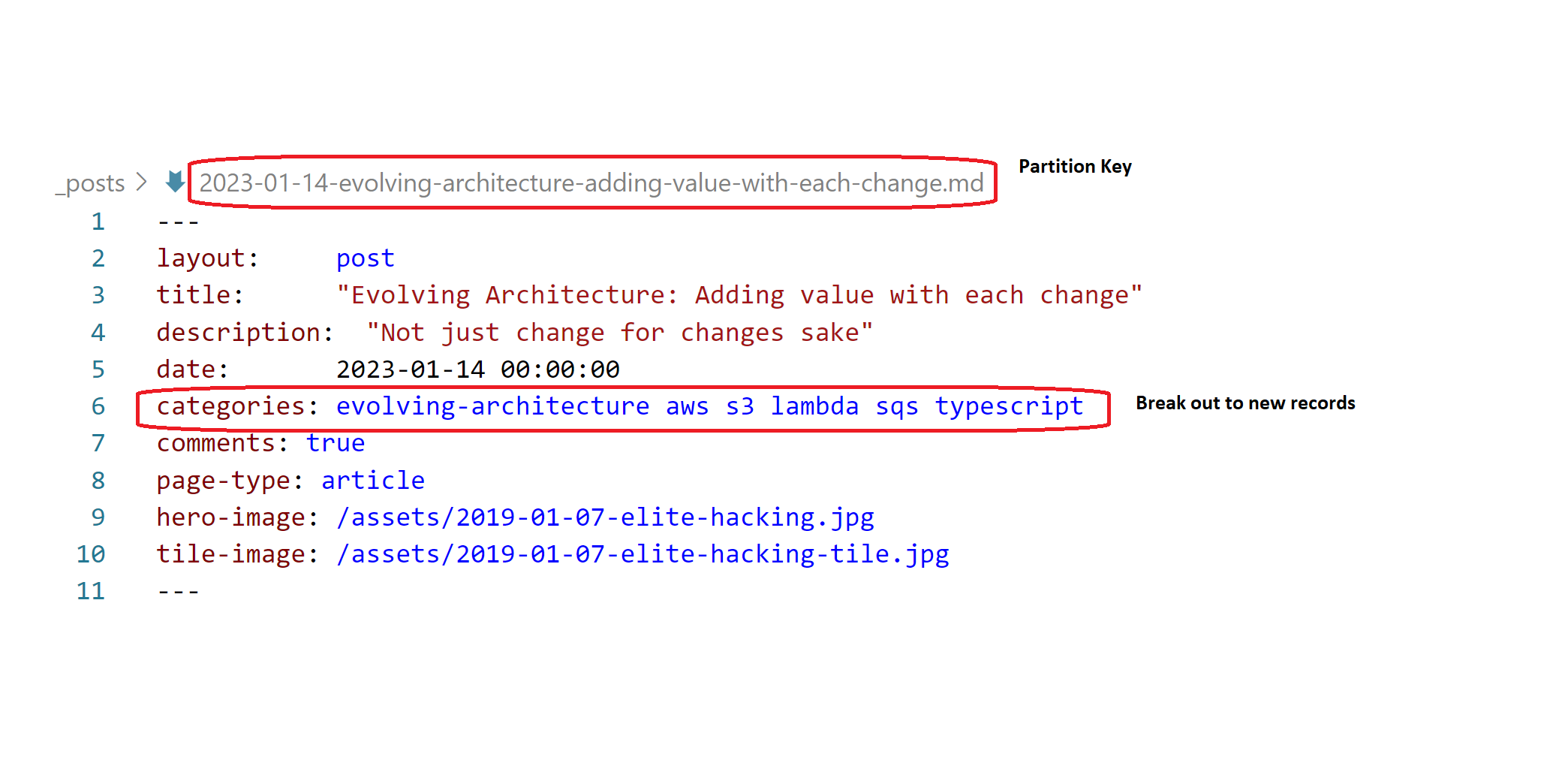
Based on this the obvious (for now) partition key is the filename, or the part before the extension. The majority of the front matter can be translated to fields in a header record. But then I’ve circled the categories header and said to break this out, but how? This is where the sort key comes in…
Partition keys and sort keys in DynamoDb can be made up of composite attributes. And indeed if make use of Global Secondary Indexes then the values in your partition key and sort key come along for free(ish).
With all of this under our belts it should come as no surprise that I’m going to be writing multiple types of records to each partition key:
meta- a record with most of the front matter key/value pairscategory#nnn- one record per category in the category list, wherennnis incremented by one for each recordcontent#nnn- one record for the content of the file, wherennnis incremented by one for each record, allowing old versions to be maintained
What next?
As I write code to deploy infrastructure, parse files, and learn more about AWS I’ll write more posts about what’s going on.